
急にあるポッドキャストのタイトルで使われている単語が何が一番多いかを分析したくなる。
全く手がかりがないので、まずはchatGPT4くんにお伺い(Bing経由)
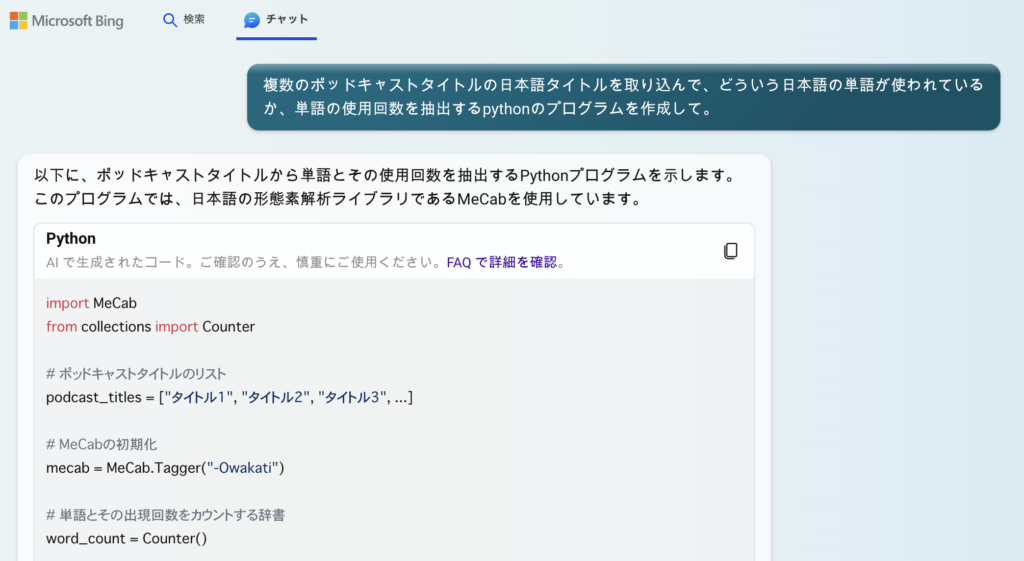
なるほど。わからん(いつもの)
ということで、色々とググってみたら、
①色々とあるんだが、mecab-python3とipadicをpythonで使えるようにするといいらしい。
②ただ、おれのM1Mac環境はconda なんだけど、そこにはどうやらデータがないらしい(pipにはある)
ということで、VScodeのJupyter環境に無理やりw
! pip install mecab-python3 , ipadic結果じゃ〜ん!!

一応入っている。(ええんかこれ?)
ということでまずは実行してみた。
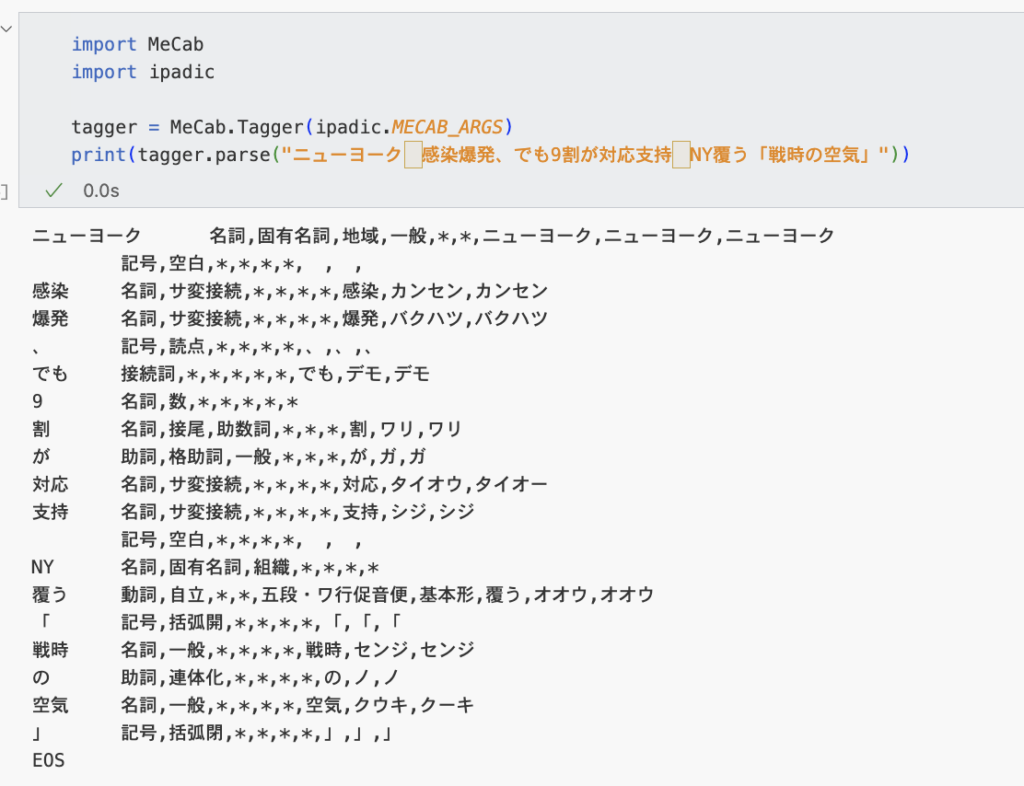
一応。多分できてる。(多分・・・)ということで、というところで、なんかとりあえず今日のところは満足してしまった・・・ということで。今日の学びは
いやならんて・・・

コメント